Another significant difference is that backface culling is enabled here. With grass the blades are essentially 2D and visible from both sides, and that means that the number of triangles sent to the GPU equals the number of potentially visible triangles, minus the blades that are off the frustum.
In case of the building block test there’s approximately half of the triangles culled away, being back-facing triangles of the boxes. The test measures number of triangles sent in draw calls, but for direct comparison with the grass test we’ll also use the visible triangle metrics.
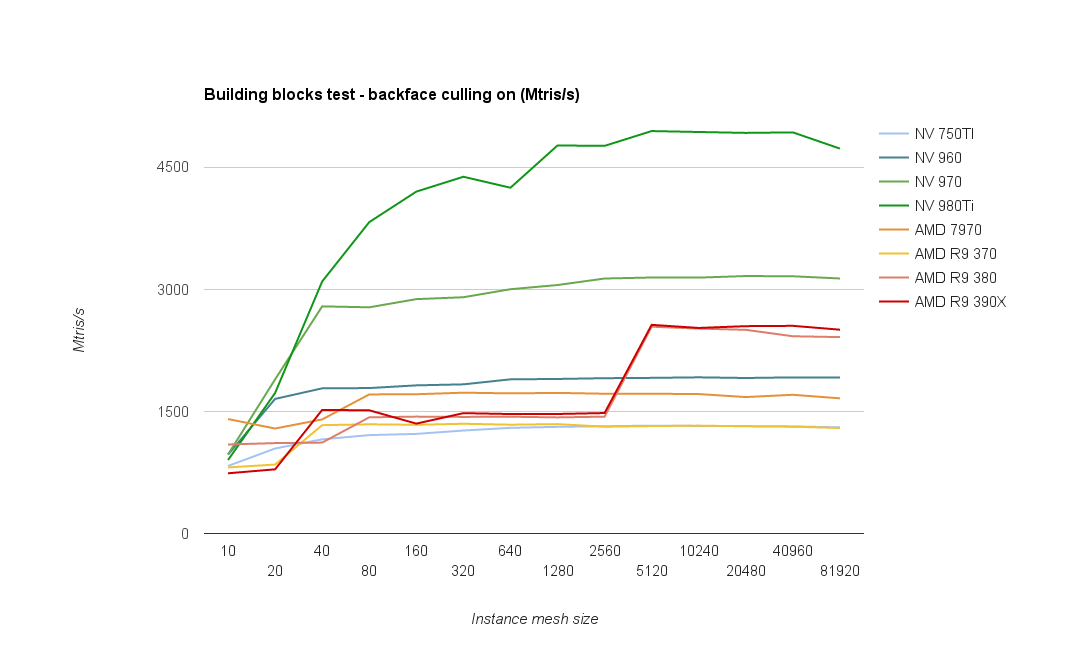
Here are the results with backface culling enabled:
(Note this graph is missing AMD Fury cards, we’d be grateful if anyone having one of these could run the test (link at the end of the blog) and submit the results to us.)
What immediately catches attention is the large boost happening on newer AMD architectures upon reaching 5k triangles per instanced draw call. A boost in that region was visible also in the grass test, though it was more gradual.
No idea what’s happening there, or rather why the performance is so low on smaller sizes. Hopefully AMD folks will be able to provide some hints.
As it was visible on the grass test as well, AMD 380/390 chips perform rather poorly on the smallest meshes (less than 40 triangles), which also corresponds to the relatively poor performance of geometry shaders.
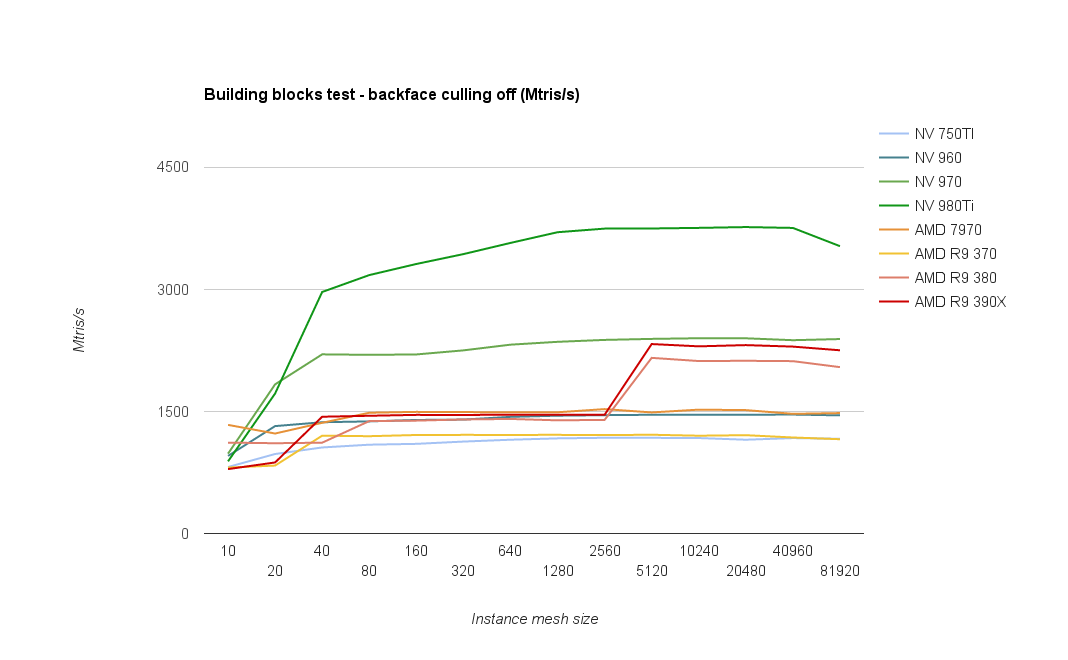
To be able to compare peak performance with the grass test we need to turn off backface culling, getting the following results:
With culling off, the GPU has to render all triangles, twice as much as in previous test. It shows on Nvidia cards, taking roughly a 30% hit.
On AMD the dip is much smaller though, indicating that maybe there’s another bottleneck.
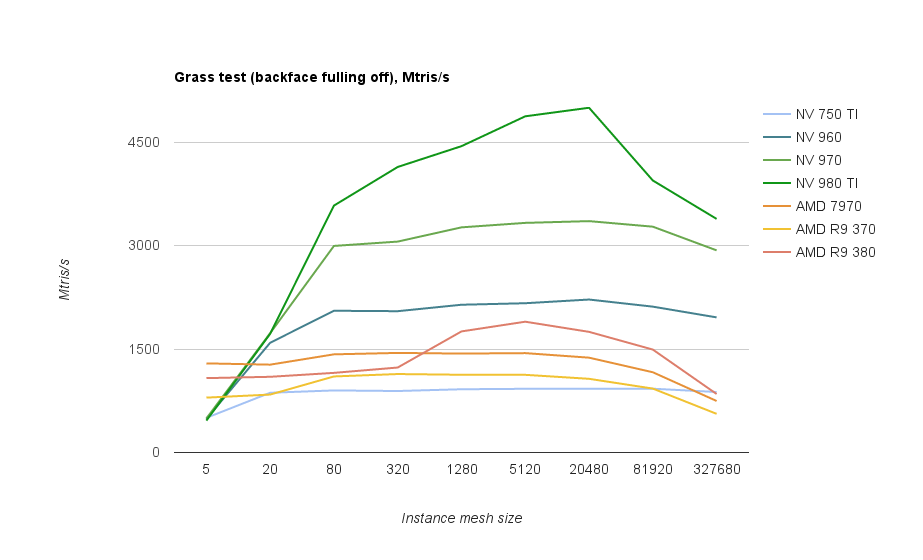
Grass test results for comparison (note slightly different instance mesh sizes). Grass test uses much less per-instance data, but has a more complex vertex shader. Apparently, it suits Nvidia cards better:
Conclusion: both vendors show the best performance when the geometry in instanced calls is grouped into 5 - 20k triangles. On AMD GCN 1.1+ chips the 5k threshold seems to be critical, with performance almost doubling.
Test sources and binaries
All tests can be found at https://github.com/hrabcak/draw_call_perf
There are 3 tests: grass, buildings and cubes. The tests can be launched by running their respective bat files. Each test run lasts only 4-5 seconds, but there are many tested combinations so the total time can be up to 15 minutes.
Once each test completes, you will be asked to submit the test results to us. The test results are stored in a CSV file, and include the GPU type, driver version and performance measurements.
We will be updating the graphs to fill the missing pieces.
Additional test results
More cards added based on test result submissions: